An introduction to LucidWorks Enterprise Search

Lucidworks Enterprise search solution is built on top of Apache Solr. It scales seamlessly w/sub-second response times under extreme query loads for multi-billion document collections. It has user friendly UI, which does all the job of configuration and search.
It is built on top of Solr, It has all its features like full-text search, result highlighting, faceted search, database integration, caching, distributed search and index replication. LucidWorks has integrated crawler which crawls the web, localsystem, database. Configure the path and schedule the duration, it will crawl and retrieve the data from the data source and index the content.
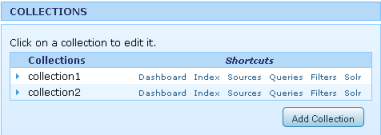
LucidWorks has its own Lucid query parser which handles all query types. It supports multiple Collections. Each collection holds a Solr index and a schema. User has an option to configure different collection for different schema and data source.
It has integrated Spell checking, Auto-complete, Click scoring support. Click scoring tracks which documents were selected by users as being relevant to their individual queries, allowing manual and automated boosting based on the popularity of a given document. Search settings, Synonym and stop words could be configured.
For developers LucidWorks Enterprise comes with free of cost. It is not open source but it is free. Programmers could leverage the complete features using its ReST API. Clients API's include JavaScript, Ruby on Rails, Java, Python, Perl , .Net/C#.
What is the purpose of Searchengine in any product? Programmer writes code to crawl the data source, retrieve the content and add it to index and provides an interface to search. LucidWorks does all this job for you. Just configure the datasource, schedule the index task and search the content.
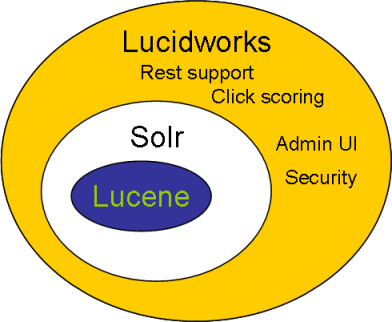
It is built on top of Solr, It has all its features like full-text search, result highlighting, faceted search, database integration, caching, distributed search and index replication. LucidWorks has integrated crawler which crawls the web, localsystem, database. Configure the path and schedule the duration, it will crawl and retrieve the data from the data source and index the content.
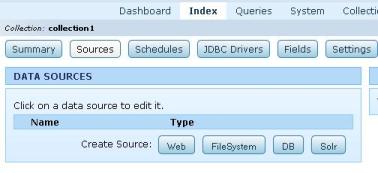
LucidWorks has its own Lucid query parser which handles all query types. It supports multiple Collections. Each collection holds a Solr index and a schema. User has an option to configure different collection for different schema and data source.
It has integrated Spell checking, Auto-complete, Click scoring support. Click scoring tracks which documents were selected by users as being relevant to their individual queries, allowing manual and automated boosting based on the popularity of a given document. Search settings, Synonym and stop words could be configured.
For developers LucidWorks Enterprise comes with free of cost. It is not open source but it is free. Programmers could leverage the complete features using its ReST API. Clients API's include JavaScript, Ruby on Rails, Java, Python, Perl , .Net/C#.
What is the purpose of Searchengine in any product? Programmer writes code to crawl the data source, retrieve the content and add it to index and provides an interface to search. LucidWorks does all this job for you. Just configure the datasource, schedule the index task and search the content.